看到今天你可能心裡滴咕著,
啊!~昨天不是說要讓我們看到數據視覺化的結果,
當然,
依照學習的進度來看確實昨天就該看到數據視覺化的股價統計表,
但,我顧慮到,如果昨天就讓你看到統計表,
今天再來說明細節,你會有耐心看完細節嗎?
答案呼之欲出,可以知道是「很難」。
由於Python不像C#、Java於for迴圈或if判斷時使用大括弧框定範圍,
因此,初學者常常會分不清程式碼的層數。
以下就是一個例子:
for date in dates:
sleep(5)
spyderData = m.spyderData(date, stock_symbol)
all.append(spyderData[0])
df_columns = spyderData[1]
all_df = pd.DataFrame(all, columns = df_columns)
print(all_df)
['20220926', '20220927', '20220928', '20220929', '20220930', '20221001', '20221003']
日期 證券代號 證券名稱 成交股數 成交筆數 ... 最後揭示買價 最後揭示買量 最後揭示賣價 最後揭示賣量 本益比
0 20220926 9914 美利達 1,627,208 1,432 ... 179.50 17 180.00 3 11.25
[1 rows x 17 columns]
日期 證券代號 證券名稱 成交股數 成交筆數 ... 最後揭示買價 最後揭示買量 最後揭示賣價 最後揭示賣量 本益比
0 20220926 9914 美利達 1,627,208 1,432 ... 179.50 17 180.00 3 11.25
1 20220927 9914 美利達 646,254 600 ... 184.00 5 184.50 1 11.57
[2 rows x 17 columns]
日期 證券代號 證券名稱 成交股數 成交筆數 ... 最後揭示買價 最後揭示買量 最後揭示賣價 最後揭示賣量 本益比
0 20220926 9914 美利達 1,627,208 1,432 ... 179.50 17 180.00 3 11.25
1 20220927 9914 美利達 646,254 600 ... 184.00 5 184.50 1 11.57
2 20220928 9914 美利達 666,197 756 ... 180.50 1 181.50 4 11.38
[3 rows x 17 columns]
日期 證券代號 證券名稱 成交股數 成交筆數 ... 最後揭示買價 最後揭示買量 最後揭示賣價 最後揭示賣量 本益比
0 20220926 9914 美利達 1,627,208 1,432 ... 179.50 17 180.00 3 11.25
1 20220927 9914 美利達 646,254 600 ... 184.00 5 184.50 1 11.57
2 20220928 9914 美利達 666,197 756 ... 180.50 1 181.50 4 11.38
3 20220929 9914 美利達 770,727 652 ... 183.50 9 184.00 4 11.50
[4 rows x 17 columns]
日期 證券代號 證券名稱 成交股數 成交筆數 ... 最後揭示買價 最後揭示買量 最後揭示賣價 最後揭示賣量 本益比
0 20220926 9914 美利達 1,627,208 1,432 ... 179.50 17 180.00 3 11.25
1 20220927 9914 美利達 646,254 600 ... 184.00 5 184.50 1 11.57
2 20220928 9914 美利達 666,197 756 ... 180.50 1 181.50 4 11.38
3 20220929 9914 美利達 770,727 652 ... 183.50 9 184.00 4 11.50
4 20220930 9914 美利達 957,208 969 ... 179.50 1 180.50 16 11.32
雖然跑迴圈,但是呈現的方式卻是每跑一次顯示一次,
所以會結果不如預期。
Python非常重視各層之間的位置,
因此程式縮排後要非常注意各層之間的對齊。
另外提醒,若遇到程式結果不如預期,
建議將相關參數以print列印出來,
不過,spyder也有好東西可以檢視變數或參數,
那就是【Variable Explorer】,可以讓bug無所遁形。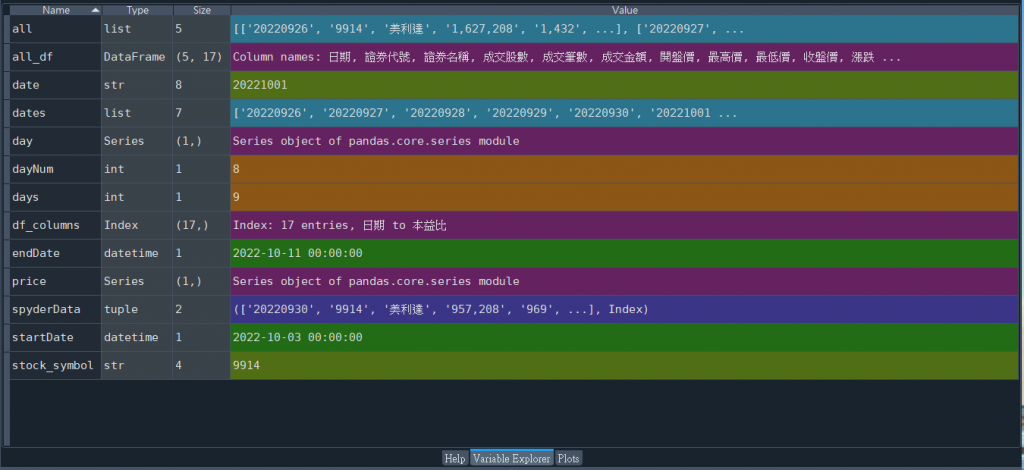
今天主要強調程式常犯的錯誤,
主要目的希望各位能避開常見的錯誤,
明天我們接著看下去。


 iThome鐵人賽
iThome鐵人賽